

Navboost, an essential part of Google’s ranking algorithm, analyzes user interactions—such as clicks, hovers, scrolls, and swipes—to refine and prioritize search results. SEOs must understand how Navboost affects ranking, as it tracks critical user signals to decide which pages are most relevant and helpful. Whether users linger on a page, return to search, or quickly find what they need, these behaviors influence how Google ranks content.
Part 1: What is this “leaked” Google documentation?
Part 2: What are attributes?
Key Takeaways
- Navboost is a critical Google ranking system that has been in use since 2005. It analyzes user behavior on search results pages to determine which content is most helpful and relevant.
- It tracks a variety of user interaction signals, including clicks, hovers, scrolls, and swipes, storing this data for 13 months to refine rankings.
- Google's system analyzes different types of clicks, such as
goodClicks,badClicks, andlastLongestClicks, to measure user satisfaction. A "long click" (where a user clicks a result and doesn't immediately return to the search page) is a strong positive signal. - Key components of Navboost include Glue, which helps rank content for fresh, real-time events, and Slices, which considers query characteristics like device type and location.
- For SEO professionals, this reinforces that optimizing for user satisfaction is essential. The focus should be on creating high-quality, engaging content that encourages users to click and stay on the page, rather than just targeting keywords.
SEO Strategies for Navboost
Actionable advice for optimizing for user satisfaction.
| Strategy | Explanation & Actionable Advice |
|---|---|
| Improve User Engagement | Create content that captures attention immediately. Aim to increase "long clicks" by providing comprehensive answers so users don't need to return to the search results. |
| Enhance Usability | Ensure your website is fast, mobile-friendly, and easy to navigate. A positive user experience encourages longer dwell times and signals satisfaction. |
| Keep Content Dynamic | Regularly update your content to keep it fresh and relevant. This is crucial for time-sensitive queries where the "Glue" component of Navboost prioritizes new information. |
| Optimize for Searchers, Not Engines | Focus on creating genuinely helpful, original, and insightful content. Ask yourself: "Is this a page someone would bookmark, share, or recommend?" This aligns with Google's Helpful Content guidelines. |
Navboost's History and Its Impact on SEO Rankings
Navboost has been a core part of Google's systems since 2005. It stores 13 months of data on what people click on and engage with from the Google search results. Prior to 2017 Navboost stored 18 months of data.
How Navboost Works
Navboost collects and analyzes a wide range of user interaction signals, including clicks, hovers, scrolls, and swipes. . This comprehensive data helps Google rank the most engaging and relevant content.
I first heard about Navboost while reading the Pandu Nayak testimony in the DOJ vs Google case. If you have not yet read this testimony, I encourage you to put aside a few hours to dig in!

The Nayak testimony starts with a discussion about user data. Did you know that for every search you perform, the actions you take on Google are monitored and anonymously stored?

Since 2005, Navboost which stores data about every single search that is performed.

What did the user click on after searching that query? Did they click on a specific website? A sitelink? A search feature? Did they click on a site and return to the search results to end up being satisfied by another? Did they swipe through a carousel? Hover over a particular SERP feature? Or perhaps did they engage with the first result and not return to search?
It’s not hard to imagine that this type of information could be used to help determine which content people are finding helpful.
An internal Google email from 2019 shows that the Navboost system was powerful.

Navboost looks at much more than just clicks. It uses a number of things that Google calls user interaction data.
Engagement signals: Clicks, hovers, scrolls and more
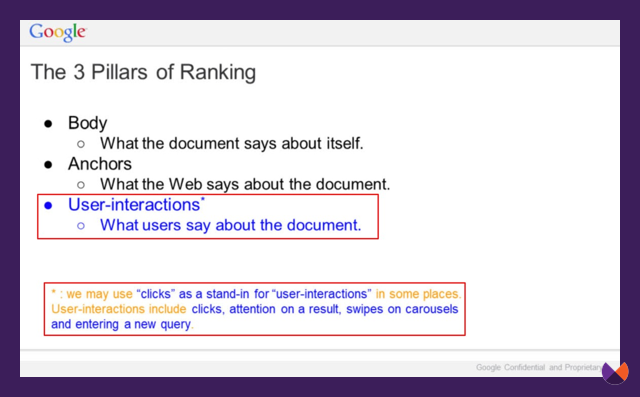
Look at these two slides from a Google presentation during the DOJ vs Google trial called, Life of a Click. I’ve marked in red boxes the parts that help us understand more about which user interactions are used by Google and why. These are referring to user interactions from within the Google Search experience - not on websites themselves. In a moment, we’ll talk about whether Google is using data from Chrome. For now though, these user engagements are referring to actions that users are taking on Google’s search results pages.
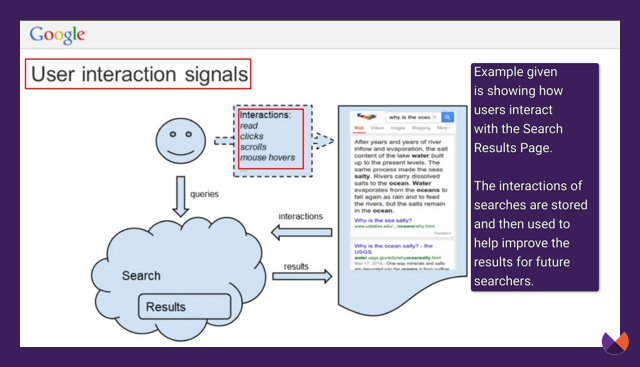
In another presentation called "Q4 Search all Hands" from 2016, Google shares how the actions of previous searchers help Google perform better for future searches.

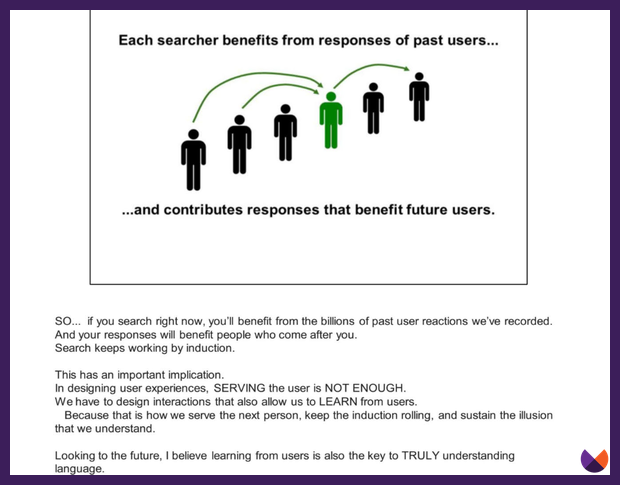
Google learns from the actions of users. While Google's doesn't specifically use CTR (Click Through Rate) as a single metric, whether people are choosing to click on your page matters!
Navboost Components: How Glue and Slices Affect SEO and Google Rankings
There are other systems mentioned in the DOJ vs Google trial that are a part of Navboost as well.
Glue is a real-time system that considers more user data such as hovers, scrolls and swipes to help the system respond to real time, fresh queries. When there is a newly changing event in the world, it is the Glue component of Navboost that helps Google adapt its algorithms to understand what content to rank.
Slices take into account certain characteristics of a search query such as the device type or location.
Navboost vs. Glue: Key Differences
A comparison of Google's user engagement systems.
| Aspect | Navboost | Glue |
|---|---|---|
| Primary Role | A core ranking system that analyzes historical user interaction data (13 months) to determine overall relevance. | A real-time component of Navboost designed to respond specifically to fresh, trending, and time-sensitive queries. |
| Data Scope | Uses long-term historical data to understand consistent user preferences. | Processes user signals as they happen to quickly adapt to new events or shifts in search interest. |
| Key Signals | Focuses heavily on click data (good, bad, long clicks) over an extended period. | Emphasizes immediate interaction signals like hovers, scrolls, and swipes for instant feedback. |
| Primary Use Case | Establishes foundational relevance for queries where user behavior is consistent over time. | Boosts or adjusts rankings for breaking news, viral topics, or events where historical data is not yet available. |
Navboost attributes that can be used in Google's search algorithms
The API docs that were discovered this year tell us a lot about the attributes that can be associated with Navboost. What I am most interested in are the attributes that have “Navboost Craps” in the name.
Understanding QualityNavboostCrapsCrapsClicksSignals

These attributes store information about clicks and impressions. There are a number of things that can be stored and used by a module called QualityNavboostCrapsCrapsData.
Here’s the documentation for this module which is used to store data related to Navboost if you want to dig in for yourself.
We learned above that every query searched on Google is stored by Navboost. There’s an attribute for that:

Several of the variables used by the Navboost module tell us about clicks. The system stores impressions, clicks, goodClicks, badClicks and more. unicornClicks are not explicity definited in the leaked documentation, and their exact nature remains a mystery. It is possible that a unicornClick might refer to an exceptionally rare or highly desireable user interaction indicating a user journey that demonstrates prfound satisfaction.

Navboost puts all of this information together and learns from it. A website that has a high number of lastLongestClicks is more likely to be one that is consistently providing the answer users are looking for. While badClicks aren’t defined in the document, it’s not hard to imagine what they are. I expect they could look at things like pogo-sticking, where users quickly return to the search results after clicking on a site and find another site that satisfies their search. A "badClick" is likely a click that didn't satisfy the user. We want to aim to have fewer of those!
I’d encourage you to spend time with Cyrus Shepard’s Moz article which looks at Google patents related to clicks: 3 Vital Click-Based Signals for SEO: First, Long, & Last.
Dwell time, the length of time a user spends on a page after clicking is important. I’d highly recommend In the Plex by Steven Levy as it talks about long clicks and short clicks. Google has been working for many years now to use this information in algorithms designed to improve its ability to return results that are likely to be helpful.
Navboost Click Attributes
A summary of click-related signals.
| Attribute Name | Inferred Meaning & Significance |
|---|---|
| impressions | The number of times a search result is shown to users on the results page. |
| clicks | The total number of times a search result is clicked by users. |
| goodClicks | Clicks that likely satisfied the user's search query, inferred as the opposite of a "bad click." |
| badClicks | Represents clicks where the user quickly returned to search results, indicating the content was not helpful. |
| lastLongestClicks | A strong positive signal where a click was the last in a session and the user stayed on the page, suggesting the query was fully answered. |
| unicornClicks | The meaning of this attribute is unknown, but may mean clicks that clearly demonstrated good user satisfaction. |
Does NavBoost use information from Chrome?
There is some debate on whether Google’s systems use information from user interaction in Chrome. It’s certainly possible, as Google’s privacy policy tells us they monitor quite a few things that we do, including how we interact with content, even looking at things like whether we hovered our mouse over an ad or if you interact with a page on which an ad is served.
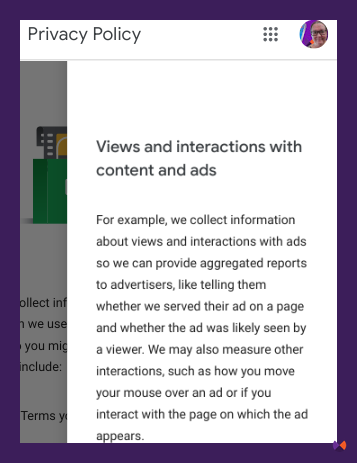
Look at all of these things that Google collects about us.
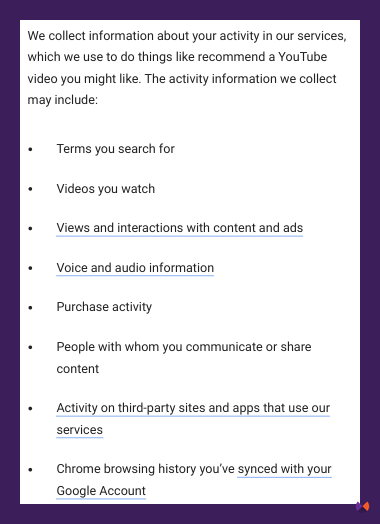
It would make sense to me that Google uses these signals to determine what people find helpful. Google knows, via Chrome, which sites people are making purchases on, which content people are sharing, and more. It’s not hard to imagine that a system could learn which of those pieces of information to use in determining whether pages are likely to be helpful and useful. What would be a better indication of the helpfulness of a recipe page - that it has links pointing to it? Or that people tend to keep the page open, hovering over the recipe section while they make the recipe, sharing it with a friend, and coming back to it repeatedly?
Here is more information on whether or not Google uses information from Chrome to measure user engagement:


SEO Focused strategies for using this understanding of Navboost
Understanding more about the Navboost system helps us to see just how important it is to focus on user experience. As we create content for the web, we need to be striving to be a result that people will often click on, and then go on to find helpful.
To improve SEO performance by understanding Navboost, focus on these actionable steps:
Improve User Engagement
Create content that engages users from the first click. Optimize for long clicks and reduce bounce rates to ensure users stay on your page.
Improve site usability
Users like fast pages that are easy to navigate and read.
Optimize for Searcher's Intent
Keep your content fresh and relevant, especially for time-sensitive queries. Navboost’s real-time adjustments mean SEOs must regularly update content to stay relevant in evolving searches.
Most importantly, Optimize for searchers rather than search engines!
Remember Google’s helpful content documentation? These questions are not a list of things that Google’s algorithms specifically reward but rather, the types of things that people tend to find helpful.
A few of the questions include:
- Does the content provide original information, reporting, research, or analysis?
- Does the content provide insightful analysis or interesting information that is beyond the obvious?
- Is this the sort of page you'd want to bookmark, share with a friend, or recommend?
- Does the content provide substantial value when compared to other pages in search results?
- If someone researched the site producing the content, would they come away with an impression that it is well-trusted or widely-recognized as an authority on its topic?
- Is this content written or reviewed by an expert or enthusiast who demonstrably knows the topic well?
These are the types of things that people like.
SEO in the age of Navboost requires a shift in focus - optimizing not just for keywords but for user satisfaction. SEOs need to create content that engages users through every click, hover, and scroll, ensuring their websites meet Google’s changing ranking signals.
There's much more on this in my book - SEO in the Gemini Era: The Story of How AI Changed Google Search.
SEO Strategies for Navboost
Actionable advice for optimizing for user satisfaction.
| Strategy | Explanation & Actionable Advice |
|---|---|
| Improve User Engagement | Create content that captures attention immediately. Aim to increase "long clicks" by providing comprehensive answers so users don't need to return to the search results. |
| Enhance Usability | Ensure your website is fast, mobile-friendly, and easy to navigate. A positive user experience encourages longer dwell times and signals satisfaction. |
| Keep Content Dynamic | Regularly update your content to keep it fresh and relevant. This is crucial for time-sensitive queries where the "Glue" component of Navboost prioritizes new information. |
| Optimize for Searchers, Not Engines | Focus on creating genuinely helpful, original, and insightful content. Ask yourself: "Is this a page someone would bookmark, share, or recommend?" This aligns with Google's Helpful Content guidelines. |
FAQ about Navboost
What are the core user signals Navboost uses for ranking?
Navboost analyzes a wide array of user interaction signals directly from Google search results, including various types of clicks (goodClicks, badClicks, lastLongestClicks), hovers over SERP elements, scrolls on content, and swipes through carousels. These behaviors provide Google with critical data to understand user satisfaction and content relevance.
How does Navboost differ from Google's 'Glue' system?
Navboost is Google's overarching system responsible for analyzing user interactions with traditional web results and storing this engagement data for up to 13 months. 'Glue' is a real-time component of Navboost, specifically designed to quickly adapt to fresh, rapidly changing queries. Glue focuses more on immediate user interactions with dynamic SERP features like carousels and 'Show more' buttons, leveraging signals like hovers and swipes to provide timely adjustments to search results.
Can I directly optimize my website for Navboost?
While you cannot directly 'optimize' for an internal Google system like Navboost, you can significantly improve your website's performance by focusing on the underlying principles Navboost measures: superior user experience and satisfaction. This involves creating highly engaging, helpful content, optimizing for long clicks, minimizing 'badClicks' (pogo-sticking), ensuring fast load times, intuitive navigation, and deeply satisfying search intent to maximize user retention and engagement after a click.
Marie Haynes' Navboost Series: Further Insights

This is part 3 of my series working to understand more about the attributes in the recently discovered Google API files. Here's the first two posts of this series if you haven't read them yet:
Part 1: What is this “leaked” Google documentation?
Part 2: What are attributes?

Comments are closed.